
What in the the world are Apache Airflow DAG Factories and why should you use them? Let’s go into what they are, why they’re used, and how they could make your life easier. We’ll also go into the nitty gritty of how to design and build one. Also, before I jump into this post, shout out to all the Airflow open-source contributors for making and maintaining such an amazing tool.
What Is A DAG Factory?
An Airflow DAG factory is a way to abstract some of your DAG’s repetitive parts and make them easier to implement for stakeholders. Take for example a Python package like Pandas. Pandas comes with about 100ish mbs of dependencies. So behind:
import pandas as pd
df = pd.DataFrame()
df["foo"]=[1,2,3]
There are hundreds of thousands of lines of code. I’m understating the complexity of the package. And yes, most of those 100 MBs are dependencies or don’t get used in the example I mentioned above.
But what I’m trying to drive home here is that hiding stuff is a key piece of software development. If your customer doesn’t care about it and will never touch it, they should never see it.
So, a DAG factory is another layer of abstraction on top of DAGs. The DAG factory will enable your users to disregard the instantiation of DAG objects. It’ll let them ignore which operators are necessary for complex workflows and will enable them to focus on what the jobs do.
So, a DAG factory lets the users own the business logic and the engineers own the mechanisms to accomplish what the business users need done.
Why Shouldn’t Engineers Own Business Logic?
Why can’t we just write Adhoc DAGs and mix in business logic? There’s nothing explicitly wrong about this. If your company has the resources to have an engineer embedded with every other team or has really technical folks on the business side, then have at it.
But in an ideal situation, everybody does what they do best and doesn’t do what they suck at. I.E. My personal goal in an organization as a data person is to enable people on the business side, analysts, data scientists, ML engineers, etc. to get as much done as humanly possible. I want to help as many people as is feasible and as much as is feasible.
Approaching this problem from a service standpoint or where I build ad-hoc ETLs is nearly impossible. Services don’t scale well without additional headcount. And headcount is always hard to get. Instead, we need to build a product and spread its adoption. Rather than help people build DAGs, we build a product that makes DAG creation super easy. Now, we only need enough engineers to build that product instead of needing an engineer or two per team for ad-hoc DAG creation.
And now, in this product world, I can focus on capturing those big workflows that happen across every other team. These might include moving data to S3 buckets, moving data to Airtable, moving data to GCS buckets, moving data to Postgres, etc.
A team may only want to provide a SQL query and point to a bucket. Whether they’ll need 1 or 5 separate operators shouldn’t make a difference. They can focus on the conext of that query and I can focus on making that pipeline stable. I’m not responsible for making the SQL output consistent, interpreting anomalies in the data, or responding to incidents for this ETL. My responsibility is all ETLs that are generated by my abstractions. If there are systematic failures in the abstraction then I’d jump in and fix them. Team’s can resolve schema issues, deciding field names, optimizing their jobs, etc.
What’s A Regular DAG Look Like?
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.bash import BashOperator
# A DAG represents a workflow, a collection of tasks
with DAG(dag_id="demo", start_date=datetime(2022, 1, 1), schedule="0 0 * * *") as dag:
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello")
@task()
def airflow():
print("airflow")
# Set dependencies between tasks
hello >> airflow()
# This example was pulled from Airflow documentation.
Here’s an example DAG from the Airflow’s docs. This is what it looks like in the Airflow UI.
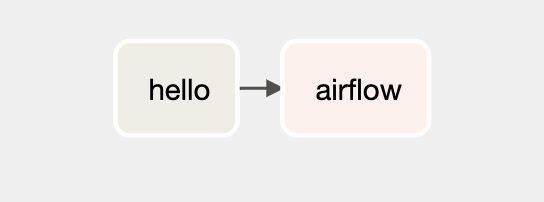
This DAG isn’t all that tough to deal with. There aren’t too many operators. The file is short. I’m not defining callback functions. So maybe creating an ad-hoc dag here might not be so bad.
But let’s spin up something more complicated.
"""
Example Airflow DAG that shows the complex DAG structure.
"""
from __future__ import annotations
import pendulum
from airflow.models.baseoperator import chain
from airflow.models.dag import DAG
from airflow.operators.bash import BashOperator
with DAG(
dag_id="example_complex",
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example", "example2", "example3"],
) as dag:
# Create
[docs] create_entry_group = BashOperator(task_id="create_entry_group", bash_command="echo create_entry_group")
create_entry_group_result = BashOperator(
task_id="create_entry_group_result", bash_command="echo create_entry_group_result"
)
create_entry_group_result2 = BashOperator(
task_id="create_entry_group_result2", bash_command="echo create_entry_group_result2"
)
create_entry_gcs = BashOperator(task_id="create_entry_gcs", bash_command="echo create_entry_gcs")
create_entry_gcs_result = BashOperator(
task_id="create_entry_gcs_result", bash_command="echo create_entry_gcs_result"
)
create_entry_gcs_result2 = BashOperator(
task_id="create_entry_gcs_result2", bash_command="echo create_entry_gcs_result2"
)
create_tag = BashOperator(task_id="create_tag", bash_command="echo create_tag")
create_tag_result = BashOperator(task_id="create_tag_result", bash_command="echo create_tag_result")
create_tag_result2 = BashOperator(task_id="create_tag_result2", bash_command="echo create_tag_result2")
create_tag_template = BashOperator(task_id="create_tag_template", bash_command="echo create_tag_template")
create_tag_template_result = BashOperator(
task_id="create_tag_template_result", bash_command="echo create_tag_template_result"
)
create_tag_template_result2 = BashOperator(
task_id="create_tag_template_result2", bash_command="echo create_tag_template_result2"
)
create_tag_template_field = BashOperator(
task_id="create_tag_template_field", bash_command="echo create_tag_template_field"
)
create_tag_template_field_result = BashOperator(
task_id="create_tag_template_field_result", bash_command="echo create_tag_template_field_result"
)
create_tag_template_field_result2 = BashOperator(
task_id="create_tag_template_field_result2", bash_command="echo create_tag_template_field_result"
)
# Delete
delete_entry = BashOperator(task_id="delete_entry", bash_command="echo delete_entry")
create_entry_gcs >> delete_entry
delete_entry_group = BashOperator(task_id="delete_entry_group", bash_command="echo delete_entry_group")
create_entry_group >> delete_entry_group
delete_tag = BashOperator(task_id="delete_tag", bash_command="echo delete_tag")
create_tag >> delete_tag
delete_tag_template_field = BashOperator(
task_id="delete_tag_template_field", bash_command="echo delete_tag_template_field"
)
delete_tag_template = BashOperator(task_id="delete_tag_template", bash_command="echo delete_tag_template")
# Get
get_entry_group = BashOperator(task_id="get_entry_group", bash_command="echo get_entry_group")
get_entry_group_result = BashOperator(
task_id="get_entry_group_result", bash_command="echo get_entry_group_result"
)
get_entry = BashOperator(task_id="get_entry", bash_command="echo get_entry")
get_entry_result = BashOperator(task_id="get_entry_result", bash_command="echo get_entry_result")
get_tag_template = BashOperator(task_id="get_tag_template", bash_command="echo get_tag_template")
get_tag_template_result = BashOperator(
task_id="get_tag_template_result", bash_command="echo get_tag_template_result"
)
# List
list_tags = BashOperator(task_id="list_tags", bash_command="echo list_tags")
list_tags_result = BashOperator(task_id="list_tags_result", bash_command="echo list_tags_result")
# Lookup
lookup_entry = BashOperator(task_id="lookup_entry", bash_command="echo lookup_entry")
lookup_entry_result = BashOperator(task_id="lookup_entry_result", bash_command="echo lookup_entry_result")
# Rename
rename_tag_template_field = BashOperator(
task_id="rename_tag_template_field", bash_command="echo rename_tag_template_field"
)
# Search
search_catalog = BashOperator(task_id="search_catalog", bash_command="echo search_catalog")
search_catalog_result = BashOperator(
task_id="search_catalog_result", bash_command="echo search_catalog_result"
)
# Update
update_entry = BashOperator(task_id="update_entry", bash_command="echo update_entry")
update_tag = BashOperator(task_id="update_tag", bash_command="echo update_tag")
update_tag_template = BashOperator(task_id="update_tag_template", bash_command="echo update_tag_template")
update_tag_template_field = BashOperator(
task_id="update_tag_template_field", bash_command="echo update_tag_template_field"
)
# Create
create_tasks = [
create_entry_group,
create_entry_gcs,
create_tag_template,
create_tag_template_field,
create_tag,
]
chain(*create_tasks)
create_entry_group >> delete_entry_group
create_entry_group >> create_entry_group_result
create_entry_group >> create_entry_group_result2
create_entry_gcs >> delete_entry
create_entry_gcs >> create_entry_gcs_result
create_entry_gcs >> create_entry_gcs_result2
create_tag_template >> delete_tag_template_field
create_tag_template >> create_tag_template_result
create_tag_template >> create_tag_template_result2
create_tag_template_field >> delete_tag_template_field
create_tag_template_field >> create_tag_template_field_result
create_tag_template_field >> create_tag_template_field_result2
create_tag >> delete_tag
create_tag >> create_tag_result
create_tag >> create_tag_result2
# Delete
delete_tasks = [
delete_tag,
delete_tag_template_field,
delete_tag_template,
delete_entry_group,
delete_entry,
]
chain(*delete_tasks)
# Get
create_tag_template >> get_tag_template >> delete_tag_template
get_tag_template >> get_tag_template_result
create_entry_gcs >> get_entry >> delete_entry
get_entry >> get_entry_result
create_entry_group >> get_entry_group >> delete_entry_group
get_entry_group >> get_entry_group_result
# List
create_tag >> list_tags >> delete_tag
list_tags >> list_tags_result
# Lookup
create_entry_gcs >> lookup_entry >> delete_entry
lookup_entry >> lookup_entry_result
# Rename
create_tag_template_field >> rename_tag_template_field >> delete_tag_template_field
# Search
chain(create_tasks, search_catalog, delete_tasks)
search_catalog >> search_catalog_result
# Update
create_entry_gcs >> update_entry >> delete_entry
create_tag >> update_tag >> delete_tag
create_tag_template >> update_tag_template >> delete_tag_template
create_tag_template_field >> update_tag_template_field >> rename_tag_template_field
Here’s what the code above looks like in the airflow UI. This is the Airflow “complex” DAG example that comes with the tool out of the box.
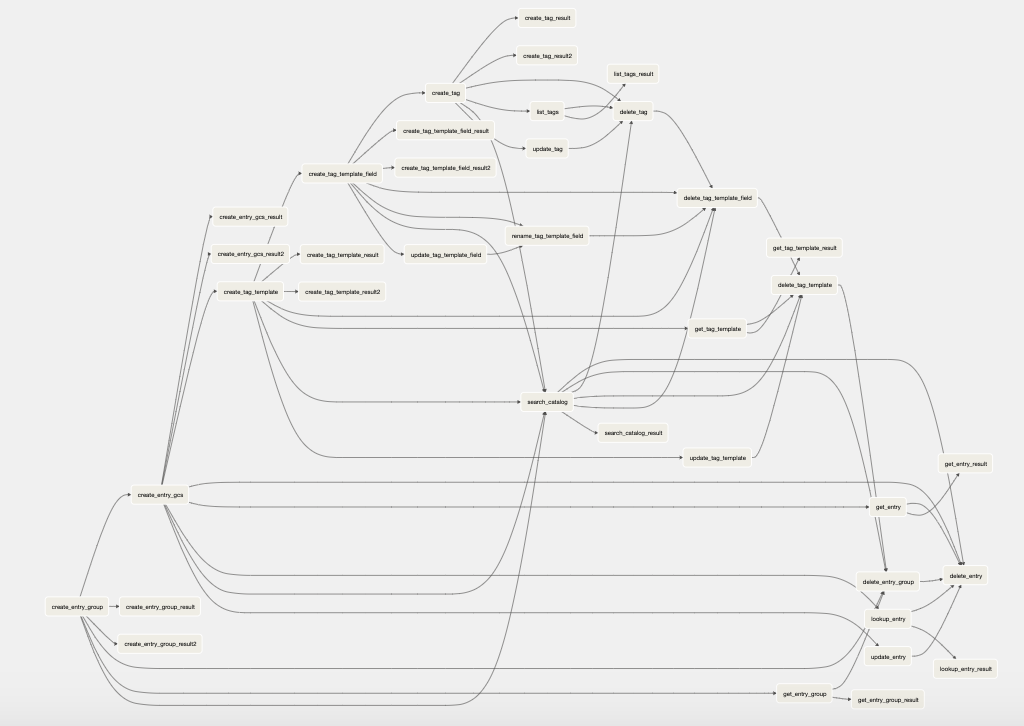
The next chunk is going to by hypothetical. Let’s say that the workflow shown above represents a business process. This is an extreme example by the way. And we start to see multiple instances of this DAG start to pop up across the Airflow deployment maybe with just a different input or with a different destination. It’s generally speaking the same-ish code but a slightly different flavor. Should we maintain 2, 3, 4, 10, 100 versions of the code? Every update to the workflow would require updating each and every file. 10-20 of them could start to fail and the other 80 could work perfectly fine. We wouldn’t know why. Is it the input changes? Or is it the manual maintenance across the 100 files? I’m betting it’s the zillions of copy+pastes.
So How Do We Get Rid Of This Repetitive Code?
Abstractionnnn or build a DAG factory. But before we start building we need to understand a couple of things.
- All python files in the
dagsfolder get executed during DAG bag parsing. We can add Python code inside the dags folder to do whatever we want during dagbag parse. In this case we’ll want to dynamically create dags. - DAGs must appear in the Airflow global variables. We’ll need to add a DAG object with the dag_id as the key to the globals dict.
The DAG Factory Design
Configs
We’ll want some code that searches for and consumes configuration files. The configuration files can be JSON, YAML, etc. JSON and YAML are two of the most common ways to define config files. Why would I pick one over the other? Let’s briefly dig into some pros and cons of both.
JSON – JavaScript Object Notation
Pros
1. Everybody knows JSON.
Most devs will have come across JSON if they’ve created REST apis. JSON is one of the most common ways for engineers to move data between machines. I.E. Backend to frontend. It’s language agnostic so regardless of what you’re writing you might be generating it. It’s biggest pro, in my opinion, is that it is so well known.
Cons
1. It isn’t very human friendly.
{
"foo": "bar",
"bar": "foo",
"foo1": {
"foo": "bar"
}
}
Fun fact. I added indentation to the JSON blob above. This makes it a bit more legible. But it’ll work without indentation. The brackets are what is used to structure the fields. Reading JSON isn’t a huge pain when it’s super small or isn’t complex. Larger JSON can get harder to read.
2. JSON doesn’t have comments.
{
"foo": "bar",
"bar": "foo",
# You would think this would work.
"foo1": {
"foo": "bar"
}
}
So the assumption that the comment above should work might tell you I’m a Python person. I 100% am. But sometimes there’s something weird in your config that you want to write a message about. “This was set to xyz date because of xyz reason.” Maybe you want to turn off a param. Well, too bad if you’re in JSON. If you want to remove a parameter, you’ll have to delete it. If you want to add a comment, you’ll have to add a new dead field.
3. JSON is Unforgiving
{
"foo": "bar",
"bar": "foo',
# You would think this would work.
"foo1": {
"foo": "bar"
}
}
The blob above is invalid JSON. The comment breaks the JSON and the single quote breaks the JSON. Stray commas can break the JSON. Many things can break the JSON. And debugging the broken JSON can get tough if it’s big.
YAML – “Yet Another Markup Language” or “YAML Ain’t Markup Language”
Pros
1. Comments
YAML let’s you comment in the file. The following should be fine as a YAML config.
# The config sets up your workflow for xyz company.
testing: "Foo"
bar: "bar"
Comments are helpful for explaining to other dev’s why decisions were made and are helpful for temporarily turning things on or off.
2. It’s Forgiving
# You can add stuff in so many ways
testing: "Foo"
bar: bar
testing1: 'test'
The config above should work fine. Single quotes, double quotes, no quotes. YAML DOESN’T CARE. Focus on the values and YAML will tackle the rest.
Cons
1. YAML isn’t as common as JSON
Fun story. The first time I saw YAML, I said something close to “wtf?” This was many years back and I just couldn’t understand what was wrong with JSON. JSON hadn’t let me down yet. Why would I need another tool? But just a few short weeks later I was in love with it. It’s just so much more aesthetically pleasing and easy on the eyes especially for a file or data that a human needs to edit. The added features are simply the cherries on top.
2. The edge cases.
There are many many edge cases that cause YAML to blow up. Check out this site which covers several of YAML’s downsides. I haven’t come across these edge cases in my day-to-day usage, but it’s best to know about them before adopting them as your data serialization format of choice.
Searching For Configs
Cool, so now you have what your configs will be stored in. It doesn’t matter what you pick. I mean you could pick both. Now, we need those configs found and consumed. Let’s use glob for the search. Put a .py file in your dags folder which includes the following:
import glob
for your_config in glob.glob("/opt/airflow/dags/**/*.yaml", recursive=True):
print(your_config)
Do note, that if you go down the JSON route, you’ll have to change the YAML mention to JSON in the snippet above.
The snippet above assumes that your configs are stored in YAML files, the YAML files are stored in the dags directory, and it’ll support nested directories.
Generating DAGs
Let’s take a second to review what your repo looks like.
- You should have Airflow up and running in Docker locally. Here’s something I wrote on that a while back if you haven’t tackled that yet. Here are the official Airflow docs on the same thing. They’re much more thorough.
- If Airflow is up and running in Docker, you should be able to visit http://localhost:8080/home.
- To make seeing your DAG factory DAGs easier, I might turn off examples. You can do this by changing
AIRFLOW__CORE__LOAD_EXAMPLESin your docker-compose.yaml file to false. - Now, here’s what my folder structure looks like.

- dagfactory.py contains the code we mentioned in the “Searching For Configs” section.
We’re missing code to translate the example.yaml config into a full-blown dag. Let’s jump into that portion. Let me highlight that the next chunk will be an extreme oversimplification of what the ensuing and eventual DAG factory will look like.
The reason I’m going to over simplify is because I want to draw a direct line between what the DAGs looked like above, and what creating the DAG factory accomplishes.
# This is used for searching
import glob
# This is used to open our config files
import yaml
# This chunk searches for every yaml file in your dags folder recursively and loops through them
for your_config in glob.glob("/opt/airflow/dags/**/*.yaml", recursive=True):
# This chunk takes the config path as input, opens the file and assigns it to config_yaml
with open(your_config, "r") as stream:
config_yaml = yaml.safe_load(stream)
print(f"dag_id: {config_yaml}")
# Here's where the ETL/DAG actually gets created.
dag = dynamically_generate_dags(config_yaml)
# We need dag_id for the globals dict
dag_id = config_yaml.get("dag_id")
print(f"dag_id: {dag_id}")
# Without this step, we wouldn't see our DAG. Here we add the dag as a global var.
globals()[dag_id] = dag
The chunk above holds everything except for the code to dynamically_generate_dags. I won’t repeat what I say in the comments.
Let’s now define the dynamically_generate_dags function. We’re going to pretty much wrap our simple dag example mentioned above in a function that will return the DAG object.
def dynamically_generate_dags(config: dict) -> DAG:
# A DAG represents a workflow, a collection of tasks
dag = DAG(dag_id=config.get("dag_id"), start_date=datetime(2022, 1, 1), schedule="0 0 * * *")
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello", dag=dag)
def airflow():
print("airflow")
airflow = PythonOperator(task_id="airflow", python_callable=airflow, dag=dag)
# Set dependencies between tasks
hello >> airflow
return dag
Let’s combine the code.
# This is used for searching
import glob
# This is used to open our config files
import yaml
# DAG Depedenencies
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
def dynamically_generate_dags(config: dict) -> DAG:
# A DAG represents a workflow, a collection of tasks
dag = DAG(dag_id=config.get("dag_id"), start_date=datetime(2022, 1, 1), schedule="0 0 * * *")
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello", dag=dag)
def airflow():
print("airflow")
airflow = PythonOperator(task_id="airflow", python_callable=airflow, dag=dag)
# Set dependencies between tasks
hello >> airflow
return dag
# This chunk searches for every yaml file in your dags folder recursively and loops through them
for your_config in glob.glob("/opt/airflow/dags/**/*.yaml", recursive=True):
# This chunk takes the config path as input, opens the file and assigns it to config_yaml
with open(your_config, "r") as stream:
config_yaml = yaml.safe_load(stream)
print(f"dag_id: {config_yaml}")
# Here's where the ETL/DAG actually gets created.
dag = dynamically_generate_dags(config_yaml)
# We need dag_id for the globals dict
dag_id = config_yaml.get("dag_id")
print(f"dag_id: {dag_id}")
# Without this step, we wouldn't see our DAG. Here we add the dag as a global var.
globals()[dag_id] = dag
Here’s what’s in my example.yaml file.
dag_id: "MySpecialDag"
param2: "s3-bucket"
param3: whatever
And here is the DAG in Airflow
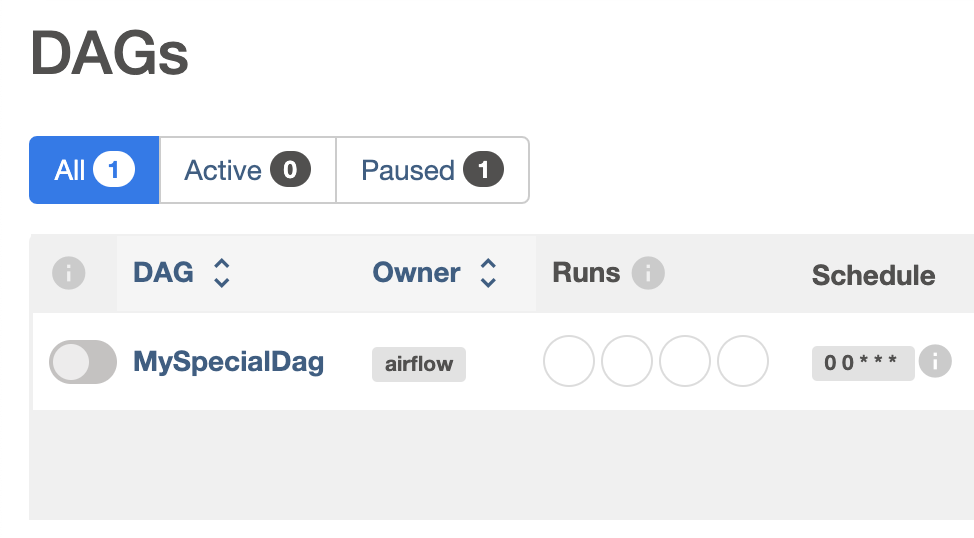
What’s Next?
You’ve created a basic DAG from a configuration file. You might now find that managing 1, 2, or 3 DAG factories might now become a pain. Some next steps in your dag factory dev life cycle might be establishing a workflow for management. Maybe instead of functions, we make the DAG creation a method of a DAG factory class? Can we deduplicate how often and how we define the DAG objects, default configs, etc? Abstracting away the boring pieces of DAG devepment won’t stop when you wrap stuff in functions. You can always make development easier, smoother, more robust. If you don’t know what’s next in your DAG factory journey ask a stakeholder or two. I’m sure they’ll have strong opinions.