
In this blog post we’re going to cover how to make your SQL queries blazing fast. So, BigQuery is an incredible tool for wrangling massive datasets and running SQL queries at scale. But let’s be honest—just because it can handle huge queries doesn’t mean you should throw inefficiency at it. The faster your queries run, the happier your users (and your wallet) will be. So let’s talk about how to squeeze every ounce of speed out of your BigQuery queries without breaking the bank.
Understand the Basics of BigQuery’s Magic
BigQuery works differently than your regular ol’ database. A few things to keep in mind:
- Columnar Storage: BigQuery only reads the columns you ask for. If you don’t need
user_birthday, don’t include it in your SELECT. (We’ll circle back to this.) - Massive Parallelism: Queries are split up and processed by a bunch of worker bees (slots). The smarter your SQL, the better those bees can do their thing.
Optimization Tricks to Speed Things Up
Here’s a grab bag of tricks you can use to make your SQL cleaner, faster, and more efficient on BigQuery.
1. Stop Using SELECT *
We all love a good SELECT *, but it’s the first step to a world of pain. BigQuery charges you for data scanned, so why pay to pull 50 columns if you only need 3? Keep it simple:
SELECT user_id, purchase_amount FROM transactions;
2. Partition and Cluster Like a Pro
If your tables are gigantic (looking at you, logs and transactions), partitioning and clustering can save your life.
- Partition Tables: Chop your data up by a field like
DATE. This lets you query just the rows you need:
SELECT COUNT(*) FROM transactions WHERE transaction_date = '2024-11-01';
- Clustering: Think of clustering as making your partitions even smarter. If you’re always filtering by
user_id, clustering byuser_idmeans faster lookups.
3. Fix Your Joins
Joins are one of the quickest ways to make your queries grind to a halt. Let’s clean them up:
- Filter Before Joining: Don’t throw the entire kitchen sink into a join. Filter your tables down first:
WITH filtered_users AS ( SELECT user_id FROM users WHERE signup_date > '2024-01-01' )
SELECT u.user_id, p.purchase_amount FROM filtered_users u JOIN purchases p ON u.user_id = p.user_id;
4. Be Kind to Your Window Functions
Window functions are awesome—until they aren’t. They can get expensive if you’re not careful.
Instead of this:
SELECT user_id, SUM(purchase_amount) OVER (PARTITION BY user_id) AS total_purchases FROM transactions;
Try pre-aggregating:
SELECT user_id, SUM(purchase_amount) AS total_purchases FROM transactions GROUP BY user_id;
5. Don’t Repeat Yourself
If you’re calculating the same thing multiple times in a query, stop. Use a WITH clause or a temp table:
WITH aggregated_data AS (
SELECT user_id, SUM(purchase_amount) AS total_purchases
FROM transactions
GROUP BY user_id
)
SELECT user_id
FROM aggregated_data
WHERE total_purchases > 1000;
It’s cleaner, faster, and easier to read.
6. Optimize Query Logic
- Eliminate Cross Joins
Avoid queries that create a Cartesian product, as they are computationally expensive.
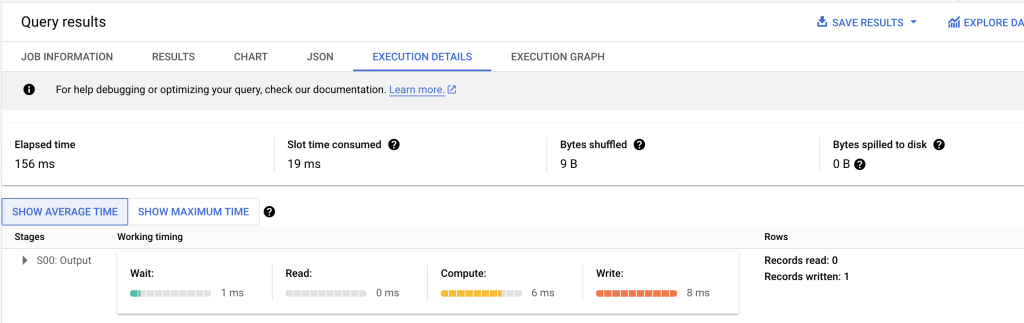
7. Keep an Eye on Query Performance
Use BigQuery’s Query Execution Details to identify bottlenecks:
- Stage Breakdown: Check which stages are consuming the most resources.
- Slot Utilization: Analyze the query’s use of processing slots to understand inefficiencies.
The Cost-Speed Balancing Act
BigQuery’s pricing is based on the volume of data processed. To keep costs low:
- Use the Query Validator:
Preview how much data your query will scan before execution in the BigQuery console.

- Set Query Limits
Use query options to restrict costs and runtime.
Conclusion
BigQuery is a beast, but you’ve got the tools to tame it. Write clean SQL, use partitioning and clustering, and let BigQuery do the heavy lifting. A little effort upfront goes a long way toward faster queries, lower costs, and happier stakeholders.
Got a query giving you trouble? Drop a comment or hit me up—I’d love to help you tune it up.